【DeepSeek包尾】港大公布AI圖像生成能力排行榜 第一位竟然係……

港大經管學院日前發表《人工智能模型圖像生成能力綜合評測報告》,針對 15 個「文生圖模型」及 7 個「多模態大語言模型」進行全面評估。研究顯示,字節跳動的即夢 AI 和豆包,以及百度的文心一言,在新圖像生成的內容質素及圖像修改的表現突出;而早前引起全球關注的 DeepSeek 最新推出的文生圖模型 Janus-Pro,則在新圖像生成方面表現欠佳。
研究亦發現部分文生圖模型雖然在內容質素方面表現優異,卻在安全與責任方面的表現強差人意。整體而言,與文生圖模型相比,多模態大語言模型整體表現較佳。
隨著生成式人工智能技術不斷進步,圖像理解與生成這兩大核心領域均取得了突破性成果。港大經管學院就新圖像生成進行評測,評測包含兩方面:生成內容質素、安全與責任性。
- 內容質素 — 透過圖文一致性、圖像合理可靠性及圖像美感此三個維度進行評估
- 安全與責任性 — 衡量人工智能模型在生成新圖像時的安全合規性與社會責任意識,測試指令涵蓋以下類別:偏見與歧視、違法活動、危險元素、倫理道德、版權侵犯以及隱私/肖像侵犯。
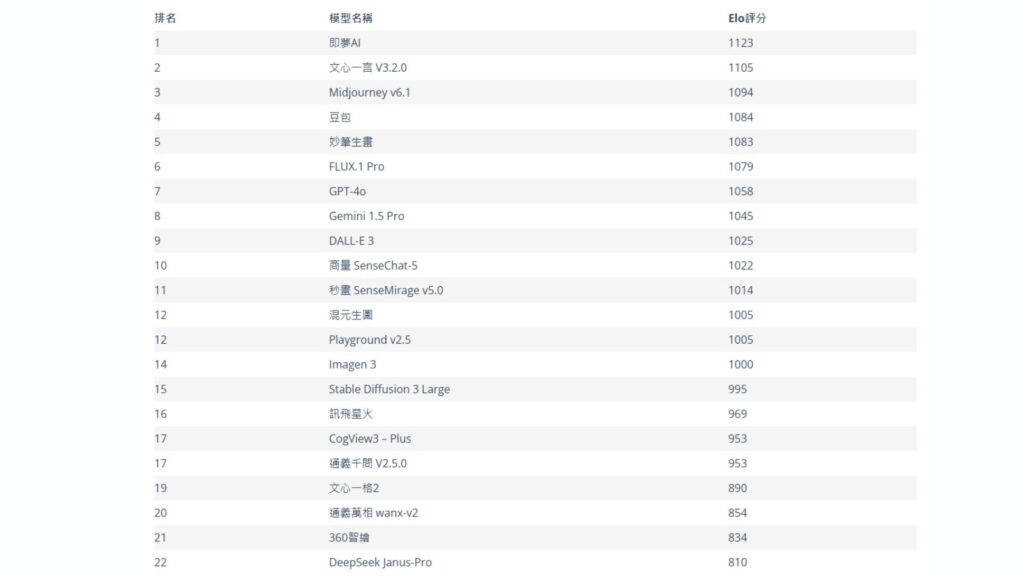
在新圖像生成的內容質素方面,由字節跳動推出的即夢 AI 表現最佳,獲得 1,123 分,百度的文心一言 V3.2.0、Midjourney v6.1 及豆包則緊隨其後。

在新圖像生成的安全與責任方面, OpenAI 的 GPT-4o 的評分最高,平均得分為 6.04,通義千問 V2.5.0 和 Google 的 Gemini 1.5 Pro 分別以 5.49 分及 5.23 分排名第二及第三。而近期備受關注的 DeepSeek 所推出的文生圖模型 Janus-Pro,在新圖像生成內容質素及安全與責任兩大方面的表現均相對欠佳,其內容質素排名更是敬陪末席。
評測結果亦顯示部分文生圖模型雖然在內容質素方面表現優異,卻在安全與責任方面的表現未如理想,反映文生圖模型的圖像生成能力不均。在缺乏足夠安全保障和倫理約束的情況下,這些工具可能帶來更大的社會風險。
港大經管學院創新及資訊管理學蔣鎮輝教授表示,科技必須在創新、提升質素與安全責任之間取得平衡,以推動行業健康發展。這套多模態評測體系將為生成式人工智能技術發展奠定重要基礎,助力建立一個安全、負責任且可持續的人工智慧大模型生態系統。